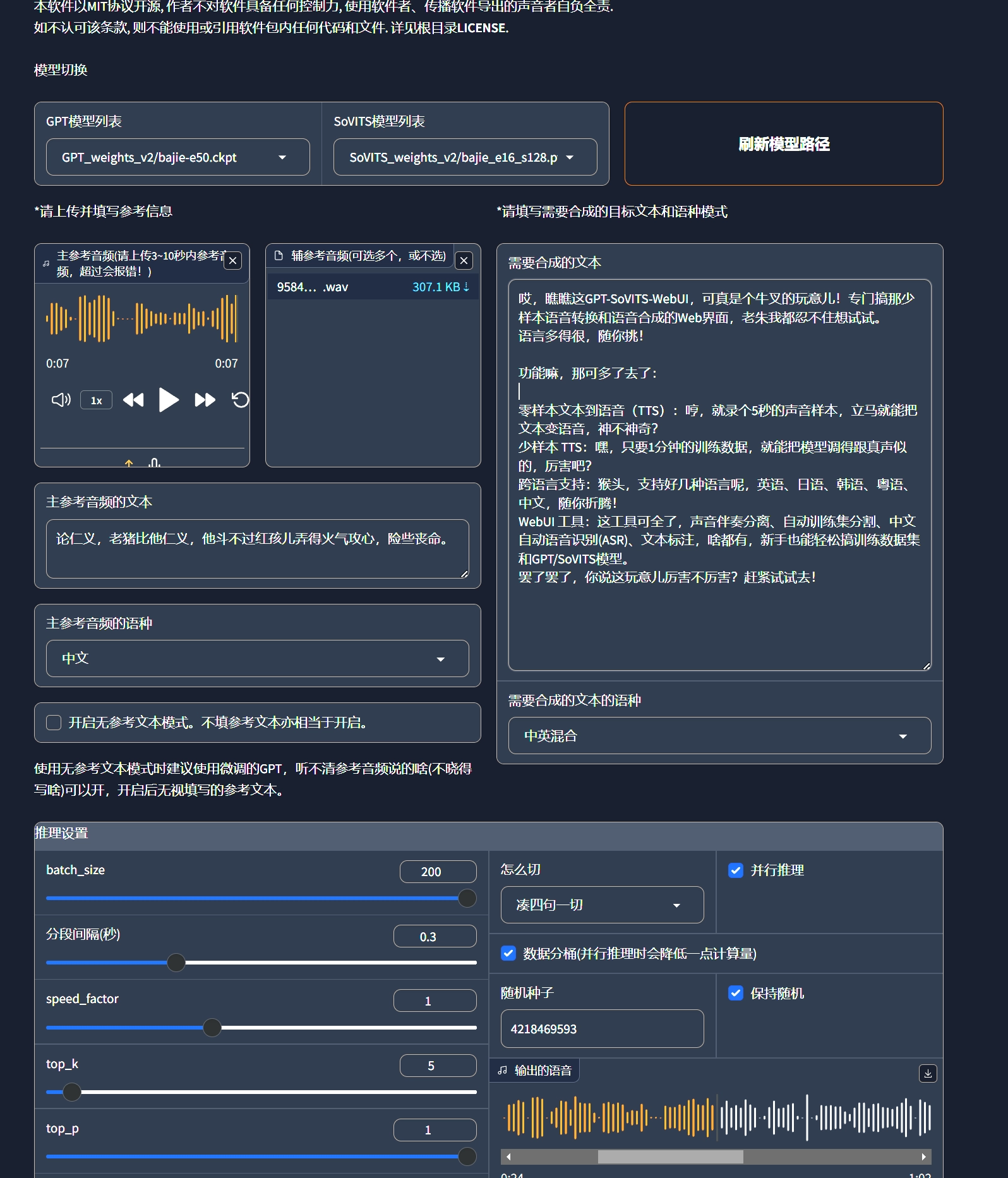
使用GPT-SoVITs 克隆语音
使用GPT-SoVITs开源项目
全流程文档:https://www.yuque.com/baicaigongchang1145haoyuangong/ib3g1e/vafogkyrwkk8rbzb#z77Su
哼,这游戏里的语音,真是干净利落,没那些杂七杂八的背景音。先用Fmodel把这宝贝语音数据掏出来,放在content-audio-soundbank文件夹里头。
音频提取
1. 游戏解包
参考游戏解包教程,使用Fmodel获取语音数据,在content-audio-soundbank文件夹内 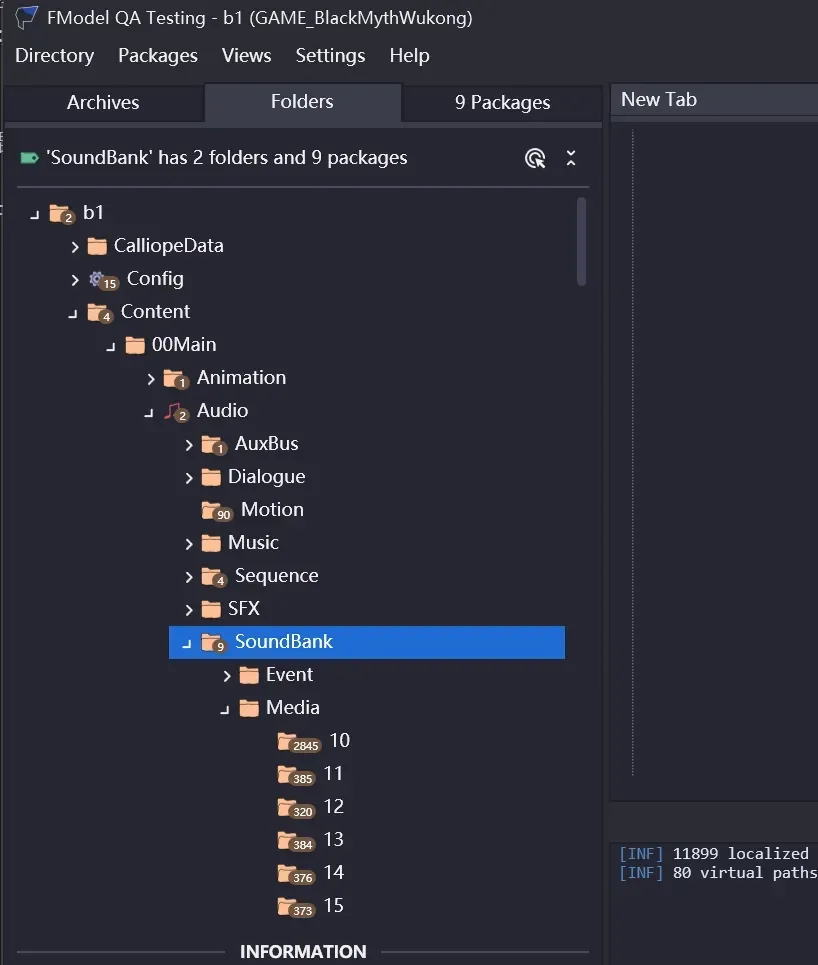
2. 音频格式转换
嘿嘿,这虚幻引擎的wem文件,得换成ogg格式才好用。
http://www.mediafire.com/file/en3m7mctkfedeju/soundMod.zip/file 原工具SoundMod不错,就是得改改convert2ogg,让它能转wem到ogg。还得加个BNK解析工具和bnk2wem.bat。
参考文章 https://www.reddit.com/r/LeaksByDaylight/comments/chnea2/how_to_convert_wem_files_to_ogg/ https://pastebin.com/wrhYYgqb http://www.aeink.com/340.html
使用方式:
- 确保BnkInput、WemInput、WemOutput这三个文件夹空空如也。
- 把.bnk文件扔进BnkInput,运行Bnk2wem.bat,生成的.wem就到WemInput里了(记得备份,转换后bnk会没掉)。
- 运行ww2ogg.bat,.wem就变.ogg了(同样,转换后wem会没掉)。
- 要直接转.wem,就从第三步开始,手动把.wem扔进WemInput。
3. 音频数据集准备
下载安装 https://github.com/RVC-Boss/GPT-SoVITS/
先用0b-语音切分工具,把音频切成10秒以内的小段。 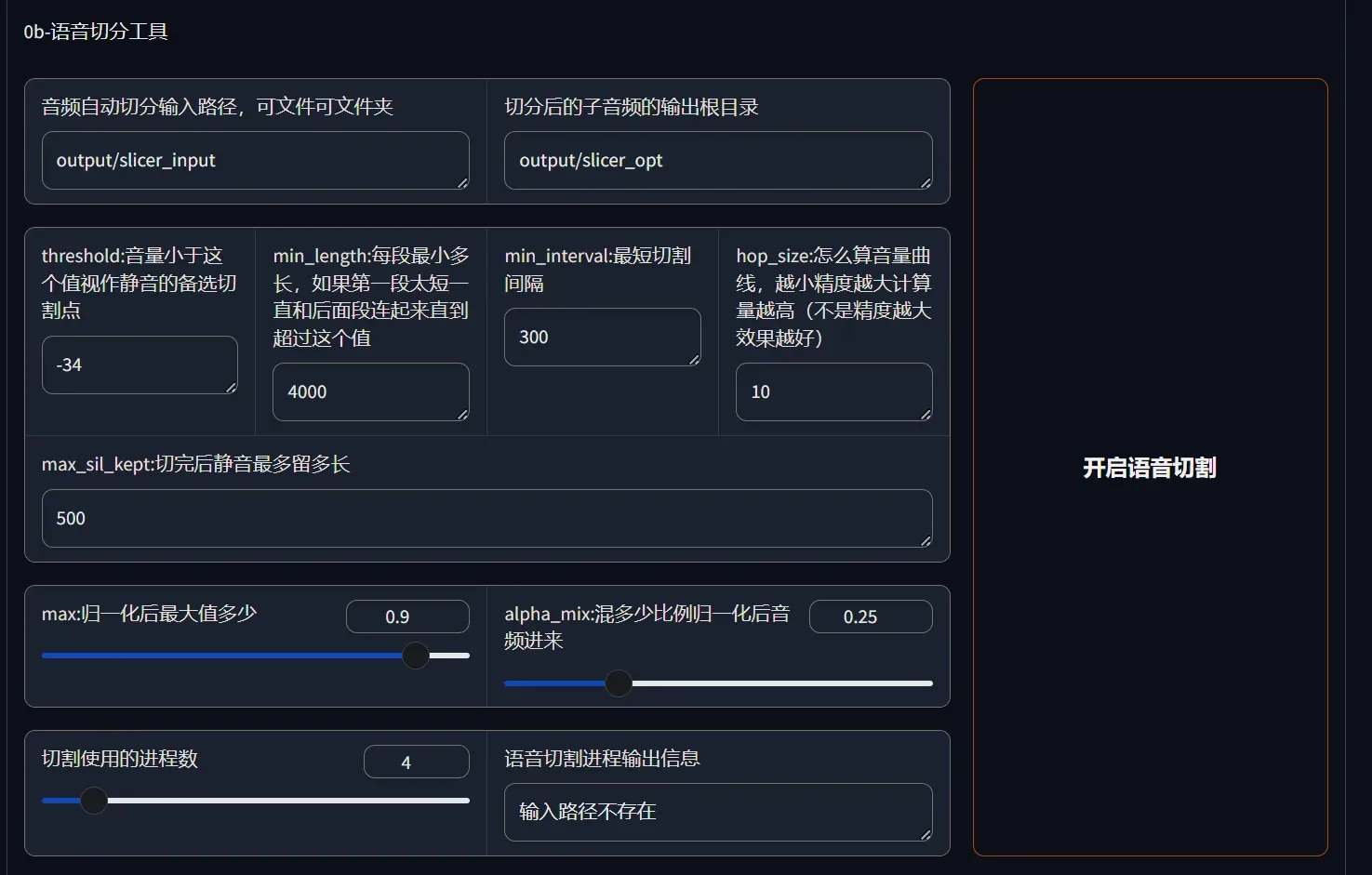
游戏语音质量好得很,降噪啥的都不用,直接ASR转文字。 直接进行ASR,将语音转成文字。(数据标注)
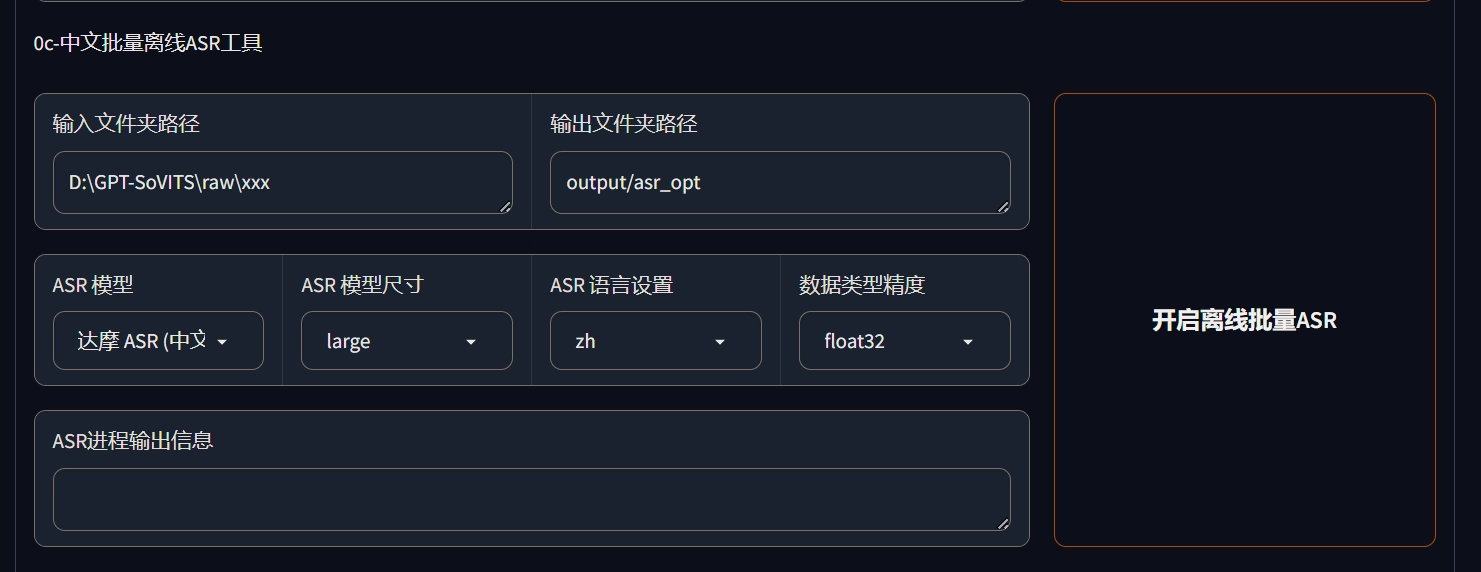
数据校对
对语音进行逐行校对,数据质量比较好,需要修改的地方不多 
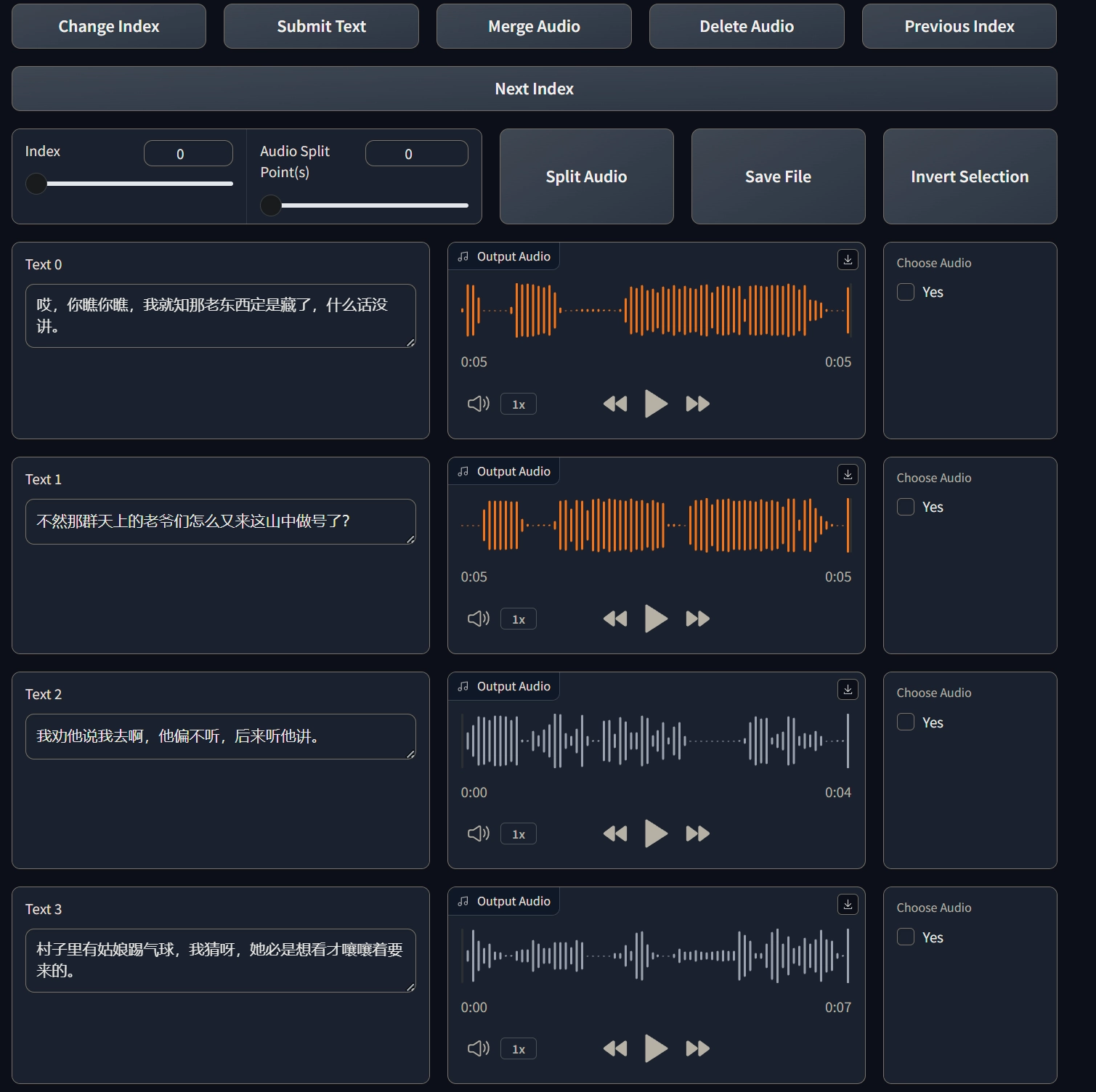
最后使用这数据集格式化工具就成了 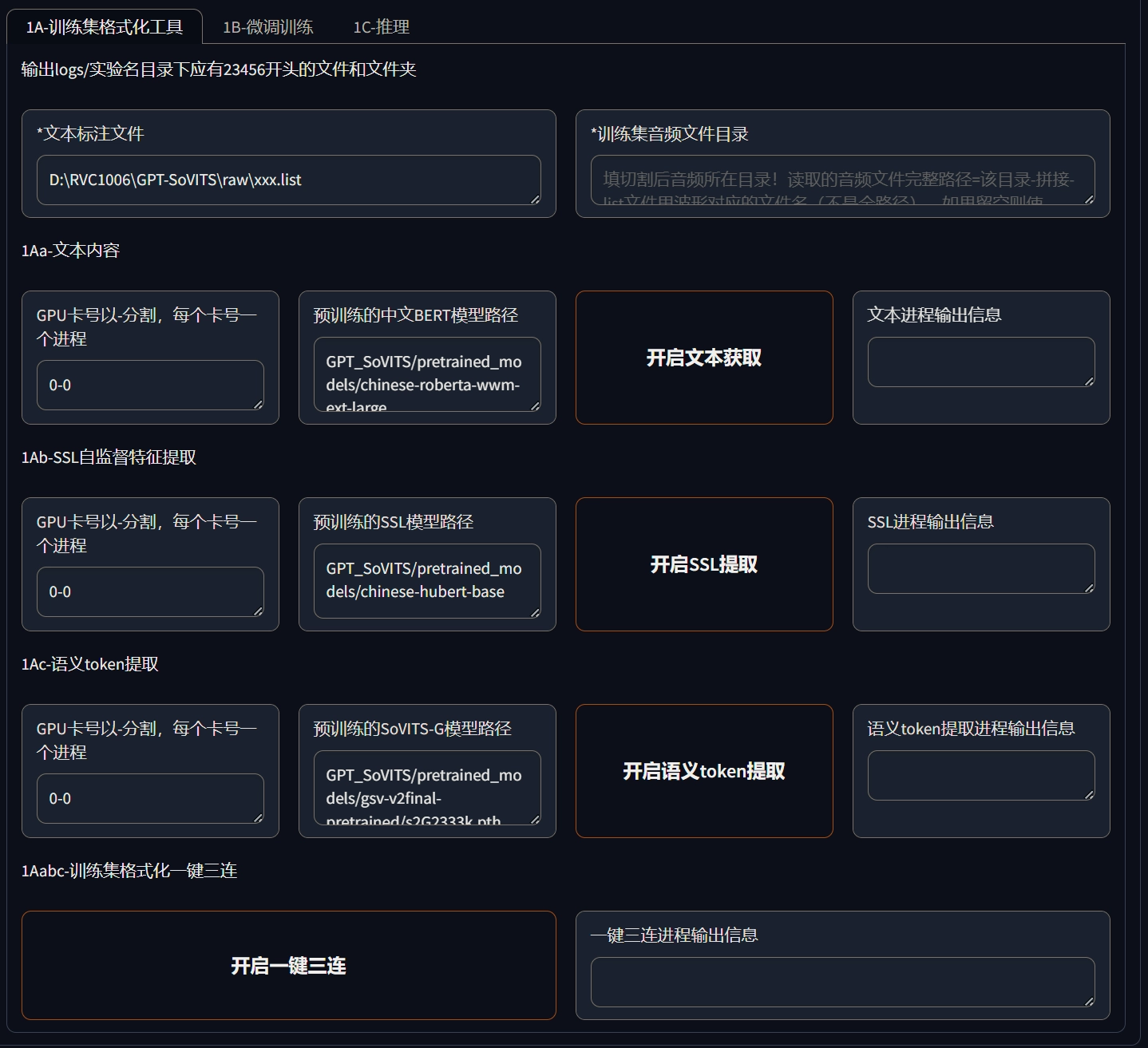
微调
训练嘛,简单得很。官方有基础模型,咱们就在这基础上微调。
先训so vits模型,按官方参数来,epoch不用太大。
再训GPT模型,开dpo,训得越长越好,当然,还得看数据集质量。
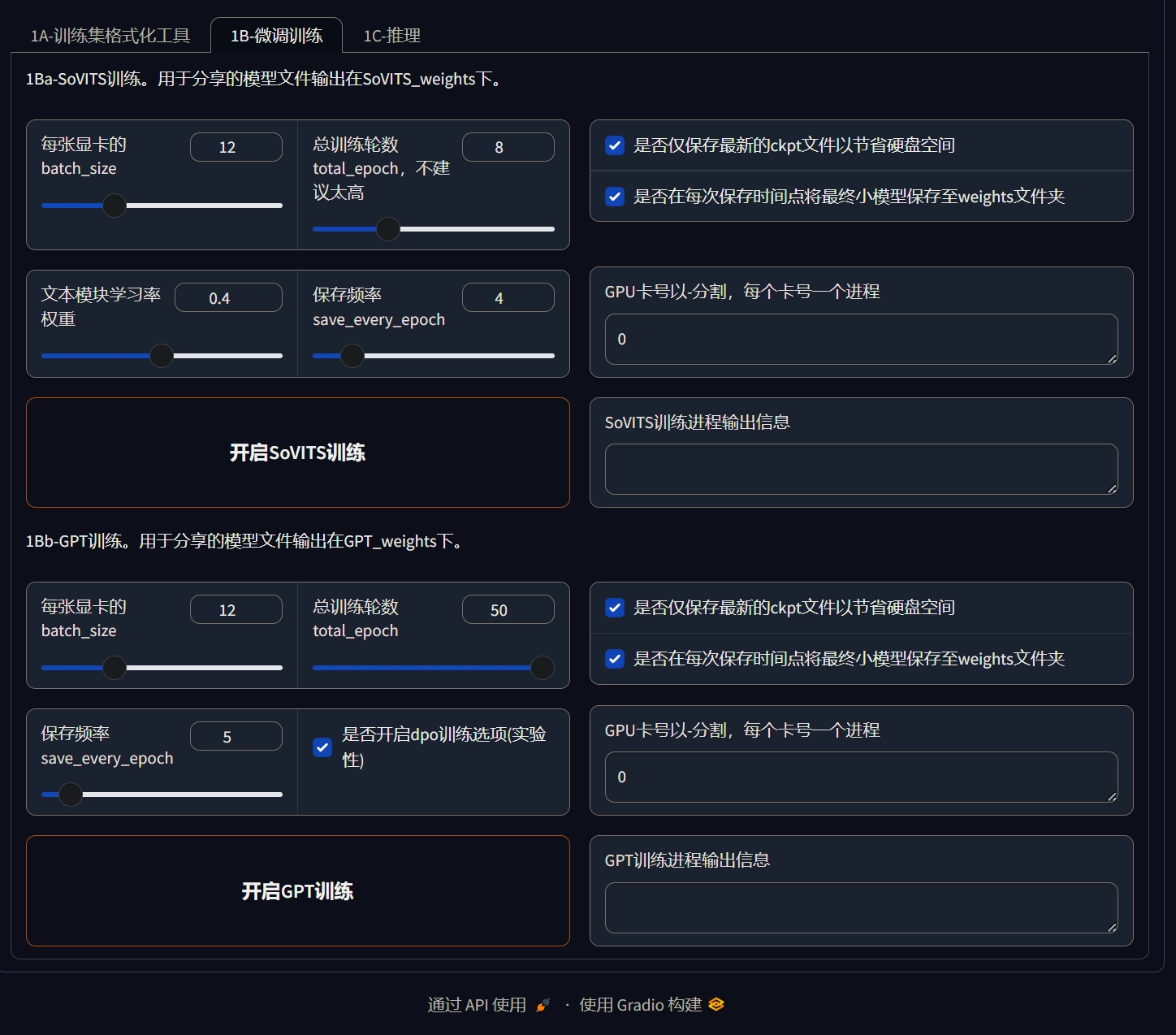
训练完成后就可以推理了 每次推理都得设参考音频,这参考音频影响情绪、语速啥的,挑几个有特色、情绪不一样的音频当参考。 合成结果:
效果不咋地?那试试:
- 用降噪工具优化数据集
- 多往数据集里添点料